
Data Platform - the centerpiece where it all comes together - Part 2
Published:
In my preceded blogpost I introduced into the basics of a modern Data Platform. In this blogpost I continue (part 2) describing the components of a data platform as well as its functionalities.
1 Components and Functions of a Data Platform
A data platform covers the tasks of, Ingestion, Storage & Compute, as well as the usage and distribution (Consumption) of digital data. Furthermore, it provides functionalities for management and orchestration (Governance & Orchestration) for data processing (see the figure below). Each of these functions is represented by specific layers, which are described in detail in the following.
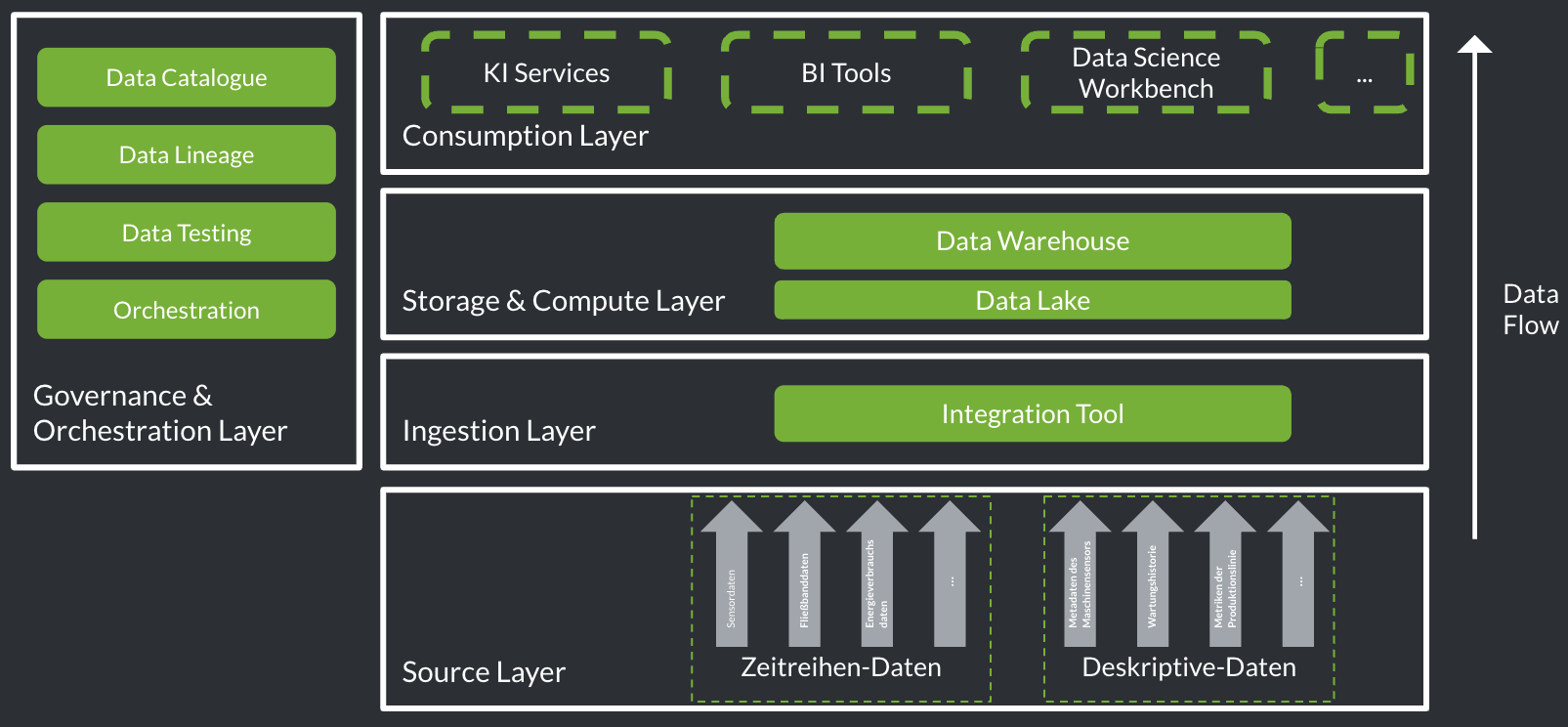
1.1 Source & Ingestion Layer
A central functionality of a data platform is the integration of digital data in various forms from diverse sources. This includes structured, semi-structured, unstructured, and descriptive data, as well as time-series data generated by sources such as databases, flat files, or sensors, which must be connected.
Two different approaches can be used to transfer data from source systems into a data platform:
- Batch Processing, where data is collected from a source at a predefined time or in predefined groupings.
- Stream Processing, where data is processed (almost) in real-time.
(1) Batch Processing
Batch processing is a method used to process large volumes of data collected and stored over a specific period all at once before passing it to an analytics system. This method requires a storage medium (database or file system) for loading and processing data, with a limited capacity. Transactions or datasets are grouped and processed together rather than individually (see Fig. 2).
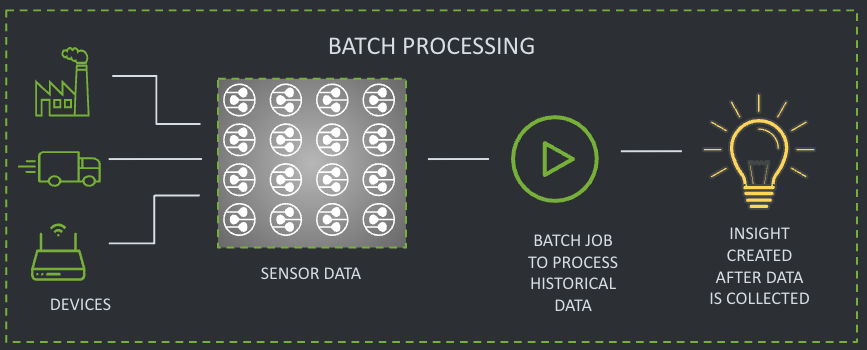
Historically, batch processing was the only available method for handling large data volumes because computers lacked the power to process data in real-time.
Today, batch processing is still used for certain industrial analytics tasks, but for most AI services requiring real-time data analysis, it has largely been replaced by stream processing.
Use Cases for Batch Processing in Industrial Analytics:
- Data Backup and Archiving (e.g., raw data backups overnight)
- ETL Processes (Extract, Transform, Load – e.g., data migration between systems)
- Report Generation (e.g., monthly maintenance reports)
- Analytics Tools for Data Insights (e.g., segmentation of industrial facilities)
- Machine Learning or Data Mining (e.g., training models for predictive maintenance)
(2) Stream Processing
Stream processing is a technique where data is processed as soon as it is needed or generated. This means that data is collected and immediately or very soon after its collection processed. This enables real-time analysis of streaming data, which is essential for many applications, especially AI-based services.
Stream processing technology is used to ensure a continuous flow of data processed in (near) real-time, allowing further utilization, report generation, or automatic responses without the need for prior downloading. Its minimal latency makes it indispensable in situations where delays could lead to negative outcomes (see Fig. 3).
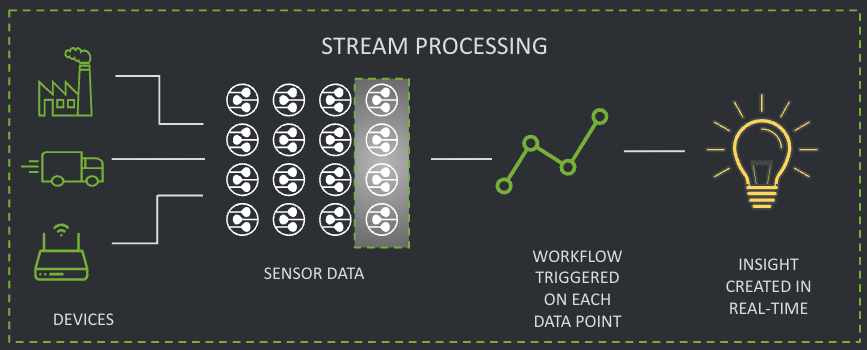
Real-time processing means that data is processed almost instantly, within milliseconds. The architecture of data streams allows data to be ingested, processed, stored, enriched, structured, and analyzed while it is in motion. A stream processor continuously reads and processes data streams from input sources according to specific rules or logic and writes the results to output streams.
Stream processors can use one or multiple threads to enable parallelism and enhance performance.
Use Cases for Stream Processing in Industrial Analytics:
- Sensor Data Analysis (e.g., anomaly detection in sensor data or real-time traffic monitoring)
- Energy Consumption Data (e.g., optimization of energy usage)
- Quality Control in Manufacturing (e.g., visual quality inspection)
- Other AI-Based Applications (e.g., solutions comparing historical and real-time data sources for analysis)
1.2 Storage & Compute Layer
Once data from various sources has been ingested, it can be persisted in different storage systems within a data platform. Subsequently, data can be transformed, processed, or cleaned before further use in the consumption layer. The following sections introduce concrete solutions and technologies for these two functional areas.
(1) Data Storage:
Several technical solutions coexist for data storage. The three most commonly used variants are Data Lake, Data Warehouse, and their hybrid form, Data Lakehouse:
Data Lake: Scalable repositories that can store various types of data in raw and native form, particularly for semi-structured and unstructured data. They generally provide unlimited storage capacity and are more cost-effective than other data storage solutions. To be truly useful, they must allow user-friendly exploration using common methods and query languages, such as SQL, automate routine data management activities, and support a range of analytical applications.
Data Warehouse: Typically used only for storing structured data, which is defined by a relational database schema. Raw data often needs to be transformed to conform to the schema. Modern data warehouses are optimized for processing thousands or even millions of queries per day and can support specific business applications.
Data Lakehouse: Cloud-based versions of these data storage options have led to hybrid solutions that combine the best features of Data Lakes and Data Warehouses. Some of these newer options are designed to store and process structured and semi-structured data, as well as key attributes of unstructured data.
(2) Data Transformation (Compute):
Data transformation is the process of preparing data for various types of usage. It may include standardization (converting all data types into the same format), cleansing (removing inconsistencies and inaccuracies), mapping (combining data elements from two or more data models), or enrichment (adding data from other sources).
Data transformation is usually required for various reasons, particularly due to specific use cases. Additionally, ensuring data quality is a key focus. Data must be cleaned to eliminate errors and duplicates, such as different spellings of names, addresses, and other anomalies. High data quality ensures accurate reports and analyses and ultimately enables advanced applications such as machine learning.
To extract, transform, and load data from different sources into a target system, two different methods can be used:
- ETL Approach (Extract, Transform, Load):
- Extracted data is structured, cleaned, and prepared for optimization in the target system.
- Transformed data is loaded into the target system, such as a Data Warehouse or Data Mart.
- Generally easier to implement than ELT since data transformation occurs in a separate step.
- Frequently used for integrating data into Data Warehouses.
- ELT Approach (Extract, Load, Transform):
- Extracted data is loaded directly into the target system without prior transformation.
- Data transformation occurs within the target system using specialized tools or scripts.
- Offers higher scalability, as data processing occurs directly in the target system, utilizing its capabilities.
- Commonly used in cloud-based systems.
1.3 Consumption Layer
The consumption layer in data platforms provides access to processed data for users and applications. It includes analytical tools such as Business Intelligence solutions, which allow users to visualize, analyze, and interpret data in various ways. Business Intelligence solutions enable users to quickly and easily create dashboards and reports to track key business metrics and make decisions. Additionally, they include AI-based services that offer product-related added value through advanced analytical functions based on machine learning (more on this in Chapter 3 AI Services).
The consumption layer enables users to utilize processed data and derive value from it.
1.4 Governance & Orchestration Layer
To establish an effective data engineering practice, it is essential to balance agility and governance. For this reason, data orchestration and governance are crucial pillars in building a robust data platform.
While comprehensive controls are necessary to ensure data cleanliness, accuracy, and timeliness, overly complex governance practices can hinder the productivity of the user community. Ultimately, the goal is to provide an agile environment that is accessible to a wide range of stakeholders, including experienced Data Engineers, Data Scientists, and occasional users who want to explore, improve, modify, and clean their data using self-service tools.
This section explains why it is important for a diverse group of individuals to enforce good data governance rules, which should create a secure and creative environment while ensuring compliance with data protection laws.
To build a successful data platform, it is crucial to treat data as a product and to use appropriate tools and technologies. In recent years, DevOps principles—originally developed to promote agile software development—have been adapted to data modeling and structuring. This has led to the emergence of the term DataOps (Data Operations), which refers to practices for automating the data development lifecycle.
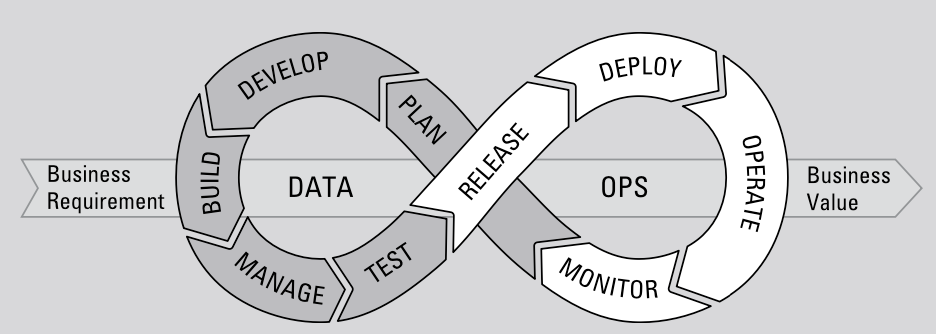
As data and analytics requirements continue to evolve, managed self-service practices and continuous DataOps deployment methods are essential to ensure that data flows correctly and is well-managed through the pipeline.
Key Aspects of Data Governance:
- Lineage: Understanding the origin, usage, and changes to data over time is important for compliance, audits, error detection, and documentation. Additionally, Data Scientists may need to trace data origins to explain their machine learning models.
- Data Quality: Trust in data is critical for the successful use of data. Unreliable data can lead to incorrect business decisions, revenue losses, and penalties for improper handling of personal data.
- Data Catalog: A data catalog with metadata and search tools helps users find and evaluate relevant data.
- Data Access: Rules must be established to determine who can access, work with, and modify data. This is particularly important for sensitive information such as personal and financial data, which may need to be anonymized or pseudonymized. Access should also be secured through multi-factor authentication (MFA) to comply with data protection regulations.
2 Summary
With these two Data Platform blogposts, you have gained an overview of the key goals and functions of a modern data platform. The platform concept, originally applied to software applications, has been transferred to the world of data. Subsequently, the objectives and requirements of data platform implementation were defined. A comprehensive description of the individual layers of a data platform, including possible technical options, can help assess where your company stands in the journey toward becoming a data-driven enterprise. Since a modern data platform serves as the foundation for data-driven decisions and AI-based services, there is no one-size-fits-all solution. Each company must determine which components are suitable for building its modern data platform based on its specific requirements and conditions.
Leave a Comment