
Using AWS Lambda with custom container image for Machine Learning inference
Published:
Using serverless offerings from cloud providers has many advantages like no provisioning and managing of servers and automatic scaling. But serverless functions also come with some limitiations like complicated deployment package management, limited package size and limited RAM. Especially if you want to use lambda functions for Machine Learning model inference, these limitations can be quite restrictive. AWS also recognized that so since December 2020 they extended their lambda offering by container image support. In this post I’ll describe my experiences using aws lambda with custom container images and describe the ups and downs of this approach.
The Challenge
Within our research project Smart Air at esentri AG we are trying to develop an AI based control of a ventilation system with integrated dehumidification for residential houses. Therefore we are doing predictions of the humidity for the following 24 hours for each room of the reference house on a continuous basis. That means every 15min we update our humidity predictions involving the new sensor data that arrived within these 15 Minutes. Therefore we trained Machine Learning models from historical data for each room. To run these predictions we could take an AWS EC2 instance, install all the necessary dependencies and trigger new predictions every 15min. But there are quite a lot of disadvantages with this approach:
- we have to pay for the EC2 instance the whole time, even though the prediction is only running every 15 Minutes for about 1 Minute (less than 7% of the time)
- we have to manage and patch the servers ourselves
- We have to think about scaling which is quite important once we extend the product to more houses
Because of these reasons we wanted to use a fully managed service paying only for the time we use the resorces and not having to think about scaling. Regarding the max runtime and RAM of AWS Lambda being clearly above the runtime and RAM requirements of our model inference AWS lambda appears to be a reasonable choice. But using lambda functions for Machine Learning inference brings its own challenges as normally you have many package dependencies. I remember projects we were cutting down packages into smaller subpackages to make them fit into the five dependency layers of aws lambda functions. This was quite a lot of work and I was glad to read at the end of 2020 that AWS introduced custorm image support which is supposed to solve the dependency problems. So I tried this “lambda with custom image” - approach and in this post I’ll describe its ups and downs.
The solution
First of all, let’s have a look at the infrastructure components and how they interact with each other in our research project:
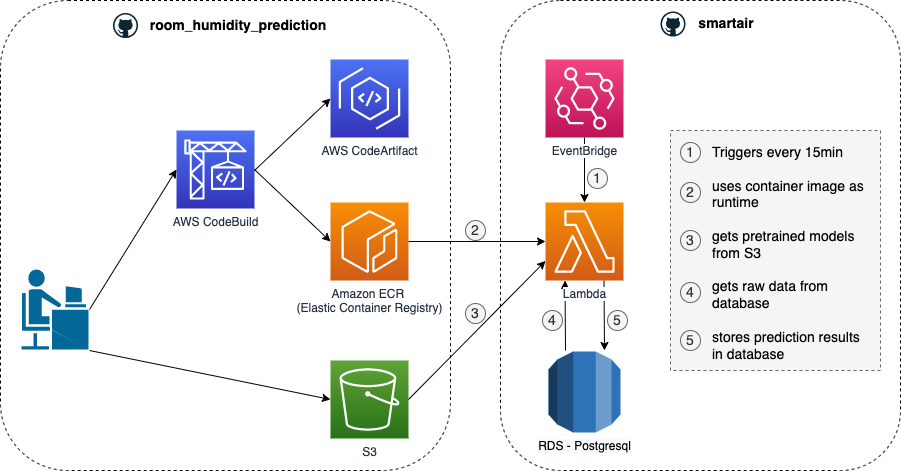
We have two separate Git-Buckets with their own CI/CD pipeline:
- Within the bucket room_humidity_prediction the whole Machine Learning logic is implemented
- Within the Bucket smartair the infrastructure code in order to do inference on a regular basis is implemented
By this means, infrastucture and logic are independent from each other and can be developed by its own. Let’s have a look at the room_humidity_prediction bucket first.
Bucket 1: room_humidity_prediction
As a developer or Data Scientist you can do two things:
- Further develop the code, e.g. adding a new feature. In our project we use semantic versioning, so if the developer tags his changes as a new version, tests will run within a AWS CodeBuild runner and if they are successful the new feature will be automatically packed and distributed to AWS CodeArtifact. Furthermore we added to our CI/CD pipeline one more step that installs our packaged code within a container that is added to AWS Elastic Container Registry
- Train/Retrain Prediction models for termperature and humidity of the single rooms of our reference house and save them to S3. So far this is a manual process which definitely can be automated in the future.
Of special interest for this blogpost is the way how to bring your package to AWS Elastic Container Registry. Therefore I first added the following Dockerfile to the repository:
FROM public.ecr.aws/lambda/python:3.8
COPY app.py ${LAMBDA_TASK_ROOT}
COPY requirements.txt .
COPY setup.py .
ADD roomidity roomidity
RUN pip3 install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
RUN python setup.py install
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "app.handler" ]
As you can see in the first line of the Dockerfile I use an AWS lambda base image for python which can be found here. Then I copy the following files and folder:
- app.py which just contains tha lambda handler function
- requirements.txt which contains the dependencies needed in order to run the room humidity prediction code which in our project is called roomidity
- setup.py which describes the roomidity package itself
- roomidity folder which contains the logic of the package
After that I first install the necessary dependencies and then the package itsef. The last line of the Docerfile hands over the entrypoint of the lambda function. That’s it for the Dockerfile.
This docker image now has to be built and brought to the AWS Elastic Container Registry. The necessary lines of code can be found in the buildspec.yaml file:
docker build -t roomidity_image .
aws ecr get-login-password | docker login --username AWS password-stdin <aws_account_id>.dkr.ecr.<region>.amazonaws.com
docker tag roomidity_image:latest <aws_account_id>.dkr.ecr.eu-central-1.amazonaws.com/smartair:latest
docker push <aws_account_id>.dkr.ecr.eu-central-1.amazonaws.com/smartair:latest
First, the image is built, than the connection between docker and AWS ECR is established and lastly the new docker image is tagged an pushed to the registry. That’s it already from the room_hunidity_prediction bucket, so lets have a look at the smartair bucket
Bucket 2: smartair
In the smartair bucket there is just pure infrastructure code, which in our project is done via terraform. For this example we added a trigger event from EventBridge and the custom image based lambda function itself including the necessary IAM permissions (the Relational Database was already deployed by another service and just accessed). As you can see in the graph above the procedure is the folowing:
- Every 15min the lambda function gets triggered
- Once it is triggered, it starts a container from the image that was created by the room_humidity_predictions CI/CD pipeline and resides in the AWS Elastic Container Registry. Within this container the app.handler function is executed
- Now it follows the logic inside the handler function and takes the pretrained models from S3 as well as the raw data from the Relational Database. With these information the inference can be done and results are saved to the Relational Database as well
Conclusion
After finding the suitable image on Dockerhub and understanding how to bring the image to AWS Elastic Container Registry I really love this approach as it has the following advantages:
- no dependency limitations: I have more than 10 subdependencies installed in the image resulting in an image of about 1GB size, which is no problem at all
- easy CI/CD integration: It is very easy to bring the image to the AWS ECR service needing just four additional lines of code in my buidlspec.yaml file, that I described above
- low cost: The container registry together with CodeArtifact cost me less than 2 Dollars a month, and the lambda functions are very cheap anyways. So I get clearly better off by using these services as by deploying everything to a continuously running EC2 instance
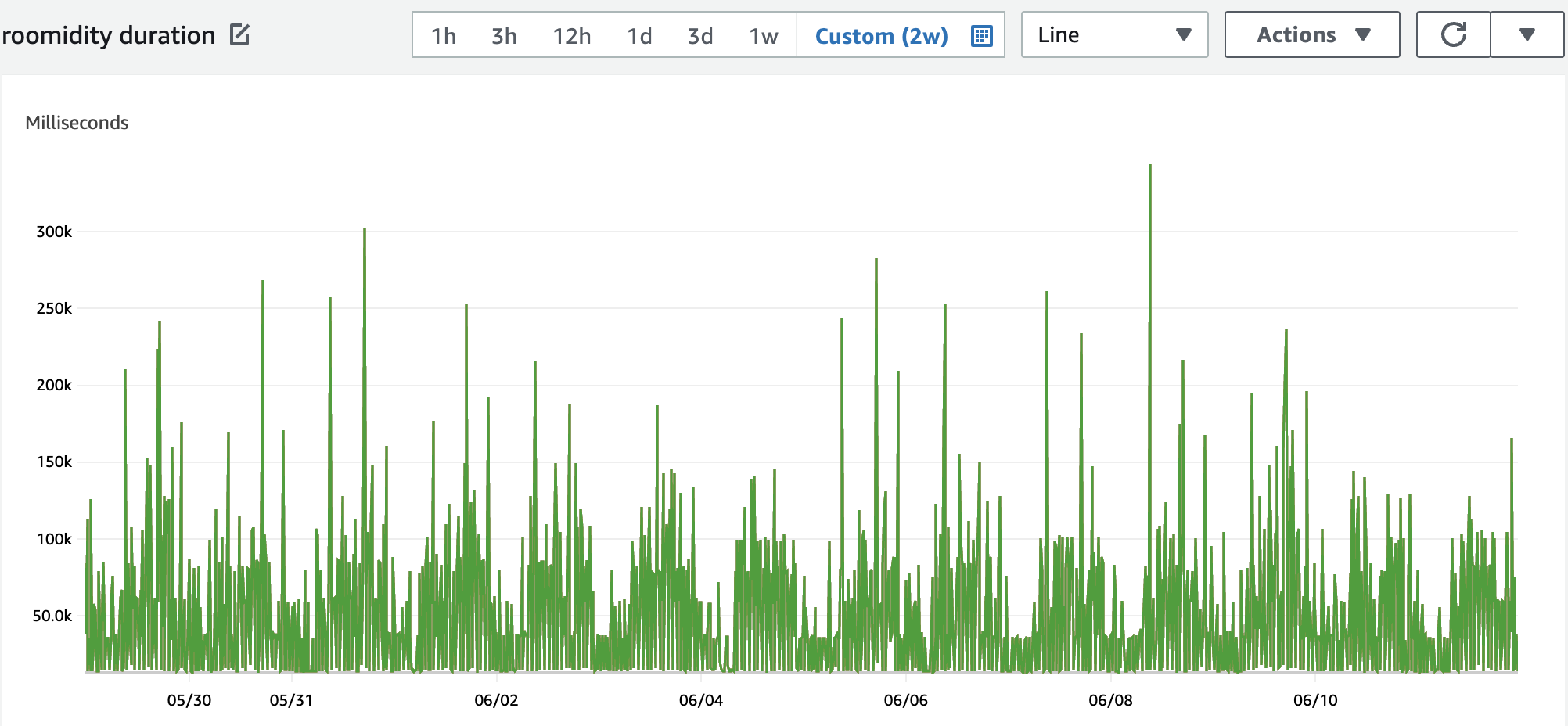
- lambda duration is ok: The average runtime of the lambda function within the last two weeks was 51.5 seconds, which is not that far from my local runtime (if I also start the container first). But the runtime is varying quite a lot as described in the “whats next” section
What’s next:
Reviewing the current infrastructure there are some things that I want to improve
- I would like to automate the model training process. So every once in a while I want to do an automated retraining as new data is collected continuously
- Furthermore, I want to try using a model registry insted of putting the trained models just to S3
- Last but not least, there is the strongly varying runtime of the lambda function that I want to investigate further. In the following graph you can see the runtime over the last two weeks:
If you have any questions / recommendations / comments /… regarding this blogpost just shoot me a message on LinkedIn.
Leave a Comment